
Relational Databases
Contents
- Contents
- Relational Databases: MySQL
- Basic Commands
- Relational Algebra
- Starting a MySQL Instance
- Entity Relationship (ER) Model
- Populating a Database
- Scripts
- Creating a DB from Scratch
- SQL Query Clauses
- Lab: Queries and Sorting
- Database Triggers
- Midterm DB (3)
- Database Transactions
- Relational Design
- Review
Relational Databases: MySQL
Guide based on Joel Murach’s MySQL (3rd Edition, 2019)
An introduction to the relational model, relational algebra, and SQL. Also covers XML data including DTDs and XML Schema for validation, and an introduction to the query and transformation languages XPath, XQuery, and XSLT. The course includes relational design principles based on dependencies and normal forms. Additional database topics introduced are indexes, views, transactions, authorization, integrity constraints, triggers, on-line analytical processing (OLAP), and emerging NoSQL (Not only SQL) databases for cloud and desktop computing.
Outcomes
- Create and assure the quality of a suitable data model for a given application.
- Use normalization to transform a relational schema into a set of normalized relations (3NF).
- Use SQL for database creation, manipulation and control.
- Employ data storage and indexing options and perform query optimization.
- Perform basic database administration tasks.
- Employ XML technologies to query, manipulate and transform data.
- Develop NoSQL desktop and cloud database solutions.
Basic Commands
to list data in a table:
SELECT * FROM table_name;
updating a table entry:
UPDATE table_name SET field='value' WHERE attribute='value';
Relational Algebra
Relational algebra is a formal and mathematical framework used to manipulate and query data stored in relational database management systems (RDBMS). It provides a set of operations and rules for working with relational databases, allowing users to retrieve, modify, and combine data in a structured and systematic way. Relational algebra serves as the foundation for SQL (Structured Query Language), which is the standard language for interacting with relational databases.
The fundamental components of relational algebra are:
-
Relations: In relational algebra, data is organized into tables called relations. Each relation consists of rows (tuples) and columns (attributes). Rows represent individual records, while columns represent the attributes or characteristics of the data.
-
Operations: Relational algebra defines various operations that can be applied to relations. These operations can be categorized into two main types:
a. Unary Operations: These operations work on a single relation.
-
Selection (σ): It selects rows from a relation that satisfy a specified condition. For example, you can use the selection operation to retrieve all customers with a certain age.
-
Projection (π): It selects specific columns (attributes) from a relation while preserving the rows. This operation helps in creating new relations with a subset of attributes.
-
Renaming (ρ): This operation is used to assign new names to relations and their attributes. It can be helpful when combining multiple relations.
b. Binary Operations: These operations involve two relations and are used to create new relations by combining or comparing existing ones.
-
Union (∪): Combines two relations to produce a new relation containing all distinct rows from both input relations.
-
Intersection (∩): Generates a new relation containing rows that are common to both input relations.
-
Set Difference (-): Produces a new relation containing rows from the first input relation that are not present in the second input relation.
-
Cartesian Product (×): Combines all possible pairs of rows from two input relations, resulting in a new relation with a potentially large number of rows.
-
Join (⨝): This operation combines rows from two relations based on a specified condition. Joins are essential for retrieving related data from multiple tables.
-
Relational algebra operations can be combined and nested to create complex queries that retrieve, transform, and filter data as needed. SQL queries are essentially expressions in relational algebra, with SQL providing a more user-friendly interface for interacting with relational databases.
| Operation | Description |
|---|---|
| Unary Operations | These operations work on a single relation. |
| Selection (σ) | It selects rows from a relation that satisfy a specified condition. For example, you can use the selection operation to retrieve all customers with a certain age. |
| Projection (π) | It selects specific columns (attributes) from a relation while preserving the rows. This operation helps in creating new relations with a subset of attributes. |
| Renaming (ρ) | This operation is used to assign new names to relations and their attributes. It can be helpful when combining multiple relations. |
| Binary Operations | These operations involve two relations and are used to create new relations by combining or comparing existing ones. |
| Union (∪) | Combines two relations to produce a new relation containing all distinct rows from both input relations. |
| Intersection (∩) | Generates a new relation containing rows that are common to both input relations. |
| Set Difference (-) | Produces a new relation containing rows from the first input relation that are not present in the second input relation. |
| Cartesian Product (×) | Combines all possible pairs of rows from two input relations, resulting in a new relation with a potentially large number of rows. For $n$ rows in $A$ and $m$ rows in $B$, $n*m$ new rows are made. |
| Join (⨝) | This operation combines rows from two relations based on a specified condition. Joins are essential for retrieving related data from multiple tables. |
In summary, relational algebra is a mathematical framework used to perform operations on relational databases. It provides a formal and systematic way to query and manipulate data stored in tables, and it forms the basis for the SQL language used in practice for working with relational databases.
Extended Projection
Creates a table with column condition , but may add in original columns i.e.: $π_{A + B -> C, A, A}(R)$ will create a column C, A, A with C values being the result of A + B.
Starting a MySQL Instance
Per instructions on mysql’s docker page, we will be making a docker compose file with the following recommended settings. This will be done on a Linux based OS:
version: '3.1'
services:
db:
image: mysql
# NOTE: use of "mysql_native_password" is not recommended: https://dev.mysql.com/doc/refman/8.0/en/upgrading-from-previous-series.html#upgrade-caching-sha2-password
# (this is just an example, not intended to be a production configuration)
command: --default-authentication-plugin=sha256_password
restart: always
environment:
MYSQL_ROOT_PASSWORD: ${ROOT_PWD}
adminer:
image: adminer
restart: always
ports:
- 8080:8080
Since mysql_native_password is not recommended as the field value for --default-authentication-plugin, so we will use one of the recommended values, sha256_password. Our root password will be stored in an environment variable called ${ROOT_PWD}, located in your .env or environment section of your container manager and will be used to log into mysql.
Now we can build it using docker compose up -d from the CLI or start it up using your container manager.
To confirm startup, we can check via docker logs my-container-name, or using docker ps, check that the container is running. You will need to run it using sudo if you haven’t added docker to your user group.

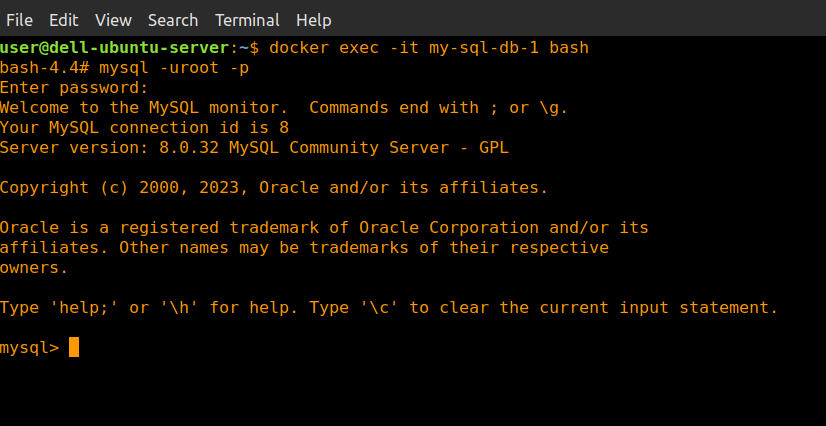
Now lets log into the MySQL database. we can access the container shell using:
docker exec -it my-sql-db-1 bash
Now we will log into the MySQL database as root by typing:
mysql -uroot -p
Entity Relationship (ER) Model
- Element Types:
- Entity and Entity Sets (Rectangle)
- similar entities == entity set
- Attributes (Ovals): qualitative descriptors
- Relationships (Diamonds)
- represented by keys for entity instance
- binary (2), tertiary(3) relationship
- symbols
- “$\circ$” indicates optional (0 instances of relationships between entities)
- “$|$” means mandatory
- “$||$” means cardinality (measure of the number of elements of a set)
- “$\triangleleft$"+"$+$” crows foot indicates many relationships (imagine $\in$ but with straight lines) $$ Attributes \in Entity \\ $$
- $R:E\rArr F$ = Each $E$ to at most one member of $F$, is “many to one”
- “one-one” is equivalent to bijection of the above relation
- “many-many” is not “many to one” bijectively
- Entity and Entity Sets (Rectangle)
ER Diagram Example
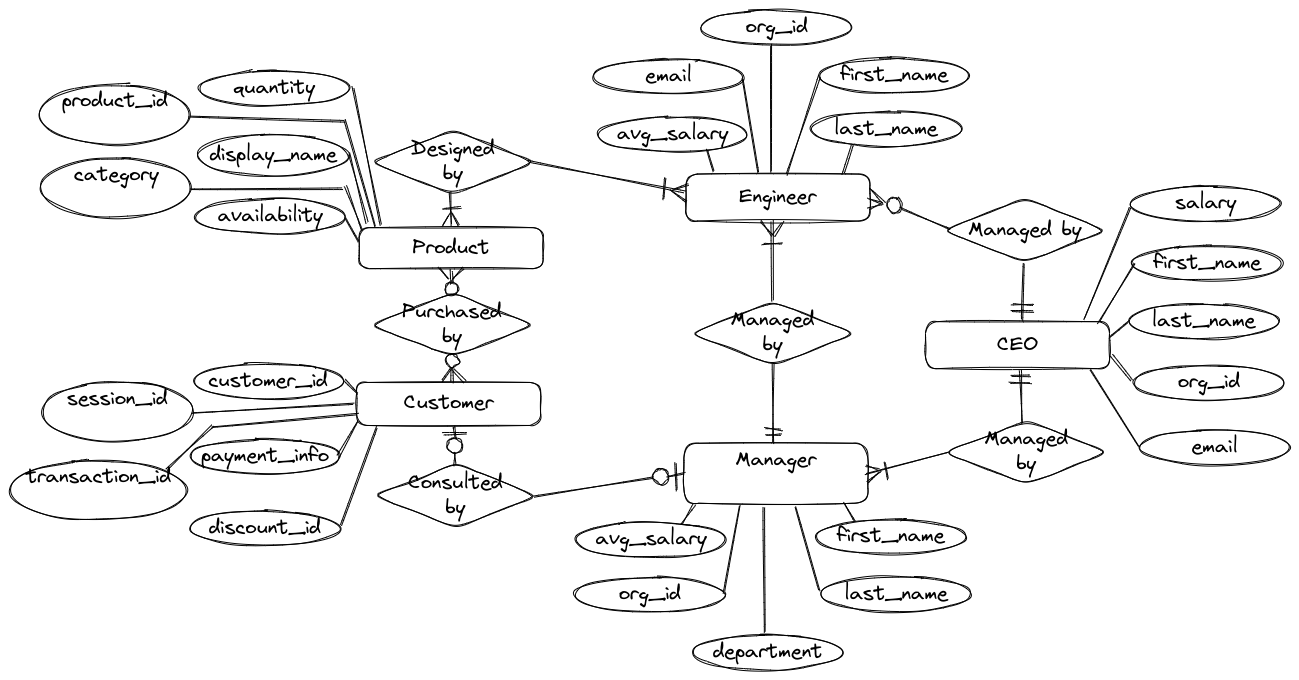
- Entities: CEO, Engineer, Manager, Customer, Product
- Attributes:
- CEO:
salary, first_name, last_name, org_id, email - Engineer:
avg_salary, first_name, last_name, org_id, email - Manager:
avg_salary, first_name, last_name, org_id, department - Customer:
customer_id, payment_info, session_id, discount_id, transaction_id - Product:
product_id, quantity, category, display_name, availability
- CEO:
- Attributes:
Populating a Database
Creating Tables
The following is an ER Diagram for the database we will be creating:
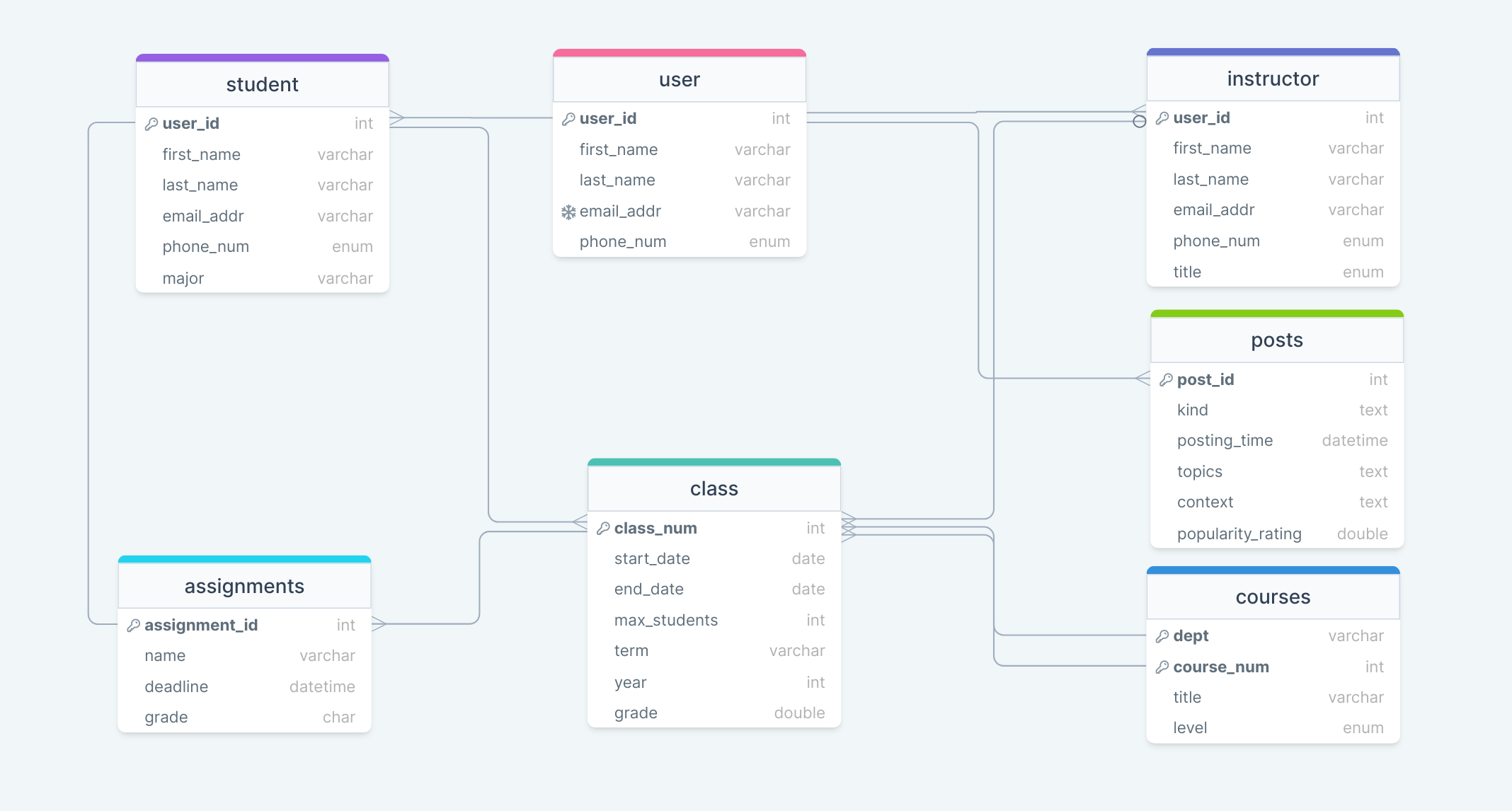
These are the following commands we will use to create our table for user, student, instructor, and courses:
create table user(user_id int primary key, first_name varchar(100), last_name varchar(100), email_addr varchar(100), phone_num enum('home','office','mobile'));
create table student(user_id int primary key, first_name varchar(100), last_name varchar(100), email_addr varchar(100), phone_num enum('home','office','mobile'),major varchar(100));
create table instructor(user_id int primary key, first_name varchar(100), last_name varchar(100), email_addr varchar(100), phone_num enum('home','office','mobile'), title enum('Full Professor','Reader','Instructor'));
create table courses(course_num int, dept varchar(100), title varchar(1000), level
enum('undergraduate','graduate','research'), primary key(course_num,department));
we can confirm with describe table_name;, like describe user;:
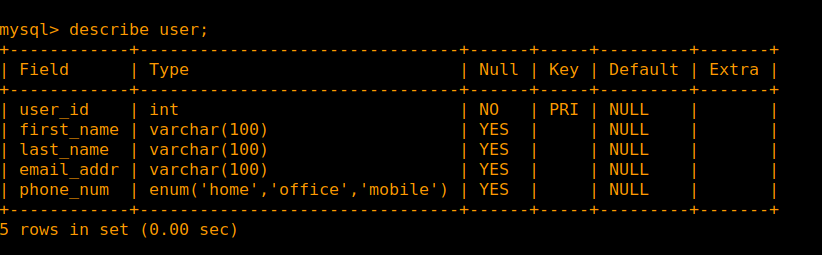
we can see, the create table user -- command created the corresponding fields and data types.
Now, let’s check what tables we have so far using show tables;:
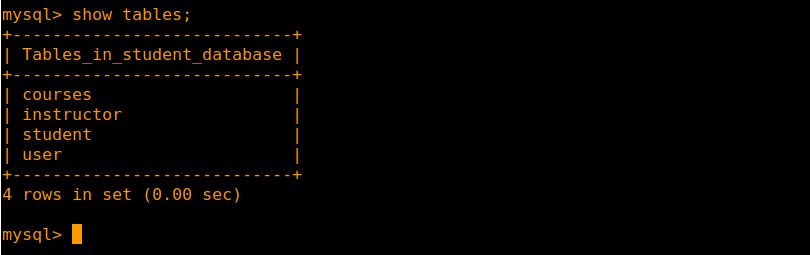
Let’s make some more tables. One for class, assignments, and posts:
create table class(class_num int primary key, start_date date, end_date date, max_students int, term varchar(100), year int, grade double);
create table assignments(assignment_id int primary key, name varchar(100), deadline datetime, grade double);
create table posts(post_id int primary key, kind text, posting_time datetime, topics text, context text, popularity_rating double);
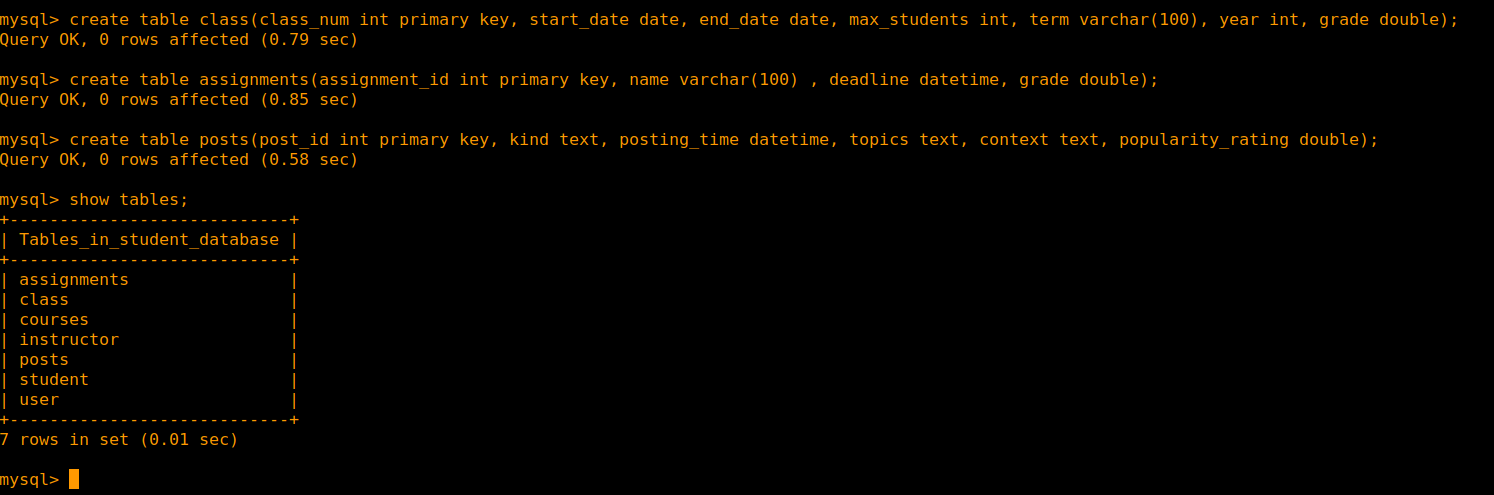
IMPORTANT
Now, how do we create relationships while creating tables? Well, we can input commands via:
CREATE TABLE accounts(
account_id INT NOT NULL AUTO_INCREMENT,
customer_id INT( 4 ) NOT NULL ,
account_type ENUM( 'savings', 'credit' ) NOT NULL,
balance FLOAT( 9 ) NOT NULL,
PRIMARY KEY ( account_id ),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
) ENGINE=INNODB;
Additional commands:
remove a column like level in courses:
mysql> alter table courses drop column level;
alter table: lets youaddordropcolumns
Creating Relationships
We will now create relationships. We will have to use ALTER TABLE commands to set up relationships for our existing tables, like so:
ALTER TABLE `table1` ADD CONSTRAINT table1_id_refs FOREIGN KEY (`table2_id`) REFERENCES `table2` (`id`);
Referenced from the documentation (MySQL 8.0 Reference Manual):
The
FOREIGN KEYandREFERENCESclauses are supported by the InnoDB and NDB storage engines, which implementADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (...) REFERENCES ... (...). See Section 13.1.20.5, “FOREIGN KEY Constraints”. For other storage engines, the clauses are parsed but ignored.For
ALTER TABLE, unlikeCREATE TABLE,ADD FOREIGN KEYignoresindex_nameif given and uses an automatically generated foreign key name. As a workaround, include theCONSTRAINTclause to specify the foreign key name:
ADD CONSTRAINT name FOREIGN KEY (....) ...
An example of usage from older docs:
ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name, ...) REFERENCES tbl_name (index_col_name,...) [ON DELETE reference_option] [ON UPDATE reference_option
FOREIGN KEY: one or more columns in a table that refer to a primary key in another table.
Important
MySQL silently ignores inline
REFERENCESspecifications, where the references are defined as part of the column specification. MySQL accepts onlyREFERENCESclauses defined as part of a separateFOREIGN KEYspecification.Note
Partitioned InnoDB tables do not support foreign keys. This restriction does not apply to NDB tables, including those explicitly partitioned by [LINEAR] KEY. For more information, see Section 24.6.2, “Partitioning Limitations Relating to Storage Engines”.
With that out of the way, let’s begin:
ALTER TABLE user ADD CONSTRAINT user_id FOREIGN KEY (user_id) REFERENCES student (user_id);
ALTER TABLE user ADD CONSTRAINT user_id FOREIGN KEY (user_id) REFERENCES instructor (user_id);
ALTER TABLE user ADD CONSTRAINT user_id FOREIGN KEY (post_id) REFERENCES posts (post_id);
ALTER TABLE student ADD CONSTRAINT user_id FOREIGN KEY (assignment_id) REFERENCES assignments (assignment_id);
ALTER TABLE student ADD CONSTRAINT user_id FOREIGN KEY (class_num) REFERENCES class (class_num);
ALTER TABLE instructor ADD CONSTRAINT user_id FOREIGN KEY (class_num) REFERENCES class (class_num);
ALTER TABLE courses ADD CONSTRAINT department FOREIGN KEY (class_num) REFERENCES class (class_num);
ALTER TABLE courses ADD CONSTRAINT course_num FOREIGN KEY (class_num) REFERENCES class (class_num);
ALTER TABLE class ADD CONSTRAINT class_num FOREIGN KEY (assignment_id) REFERENCES assignments (assignment_id);
Scripts
We will be loading a script into our docker container. SSH into the server and create a file that will house our script.
touch myscript.sql
nano myscript.sql
docker cp myscript.sql container_id:/{directory}/myscript.sql
Now, it should copy the file straight into the root directory or inside {directory} in your root directory. The full workings of this command is:
docker cp {myfile.ext} {container name}:/{directory}/{myfileout.ext}
To run the script, we use source and set the path in mySQL.
source /{directory/{script.sql}
Creating a DB from Scratch
create a database “mysqldev”:
create database mysqldev;
use mysqldev;
create table and specify InnoDB engine:
create table ADDRESS(ADDRESS_ID INT, ADDRESS_LINE1 VARCHAR(100), ADDRESS_LINE2 VARCHAR(100), CITY VARCHAR(100), STATE_CD VARCHAR(2), PRIMARY KEY (ADDRESS_ID)) ENGINE=INNODB;
confirm table is made to specification:
show tables;
describe ADDRESS;
create an “ORDER” table. Because order is a keyword, we must use backticks:
create table `ORDER`(ORDER_ID INT, PRODUCT_CODE VARCHAR(100), PRODUCT_DESCRIPTION VARCHAR(100), TRANSACTION_DATE DATE, PRIMARY KEY (ORDER_ID)) ENGINE=INNODB;
create a “CUSTOMER” table:
create table CUSTOMER(CUSTOMER_ID INT, FIRST_NAME VARCHAR(100), LAST_NAME VARCHAR(100), EMAIL VARCHAR(100), PHONE VARCHAR(100), DATE_PURCHASED DATE, ADDRESS_ID INT, ORDER_ID INT, PRIMARY KEY (CUSTOMER_ID)) ENGINE=INNODB;
create foreign key on ADDRESS_ID referring to ADDRESS TABLE, and a foreign key on ORDER_ID referring to ORDER TABLE, as well as a unique constraint on EMAIL column.
We’ve already added primary keys, but can do it again as a learning experience in addition to adding foreign keys and unique constraints:
ALTER TABLE CUSTOMER ADD CONSTRAINT FK_ADDRESS_ID FOREIGN KEY (ADDRESS_ID) REFERENCES ADDRESS(ADDRESS_ID);
ALTER TABLE CUSTOMER ADD CONSTRAINT FK_ORDER_ID FOREIGN KEY (ORDER_ID) REFERENCES `ORDER`(ORDER_ID);
// don't need to do this!
ALTER TABLE ADDRESS ADD CONSTRAINT PK_ADDRESS_ID PRIMARY KEY(ADDRESS_ID);
// don't need to do this!
ALTER TABLE CUSTOMER ADD CONSTRAINT PK_CUSTOMER_ID PRIMARY KEY(CUSTOMER_ID);
// don't need to do this!
ALTER TABLE `ORDER` ADD CONSTRAINT PK_ORDER_ID PRIMARY KEY(ORDER_ID);
ALTER TABLE CUSTOMER ADD CONSTRAINT EMAIL_UNIQUE UNIQUE (EMAIL);
SQL Query Clauses
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
Lab: Queries and Sorting
Using a database. For example studentdb which has tables STUDENT, grade_event, and score. (1)
USE studentdb; -- use the db
SHOW tables; -- show tables present i.e. STUDENT, ...
Displaying COUNT of rows (2)
Perhaps we want to know how many rows exist in each table. We can obtain this via COUNT() which counts the number of rows:
mysql> SELECT COUNT(*) FROM STUDENT;
+----------+
| COUNT(*) |
+----------+
| 31 |
+----------+
we can display the COUNT of all rows similarly:
mysql> SELECT COUNT(*) FROM grade_event;
+----------+
| COUNT(*) |
+----------+
| 6 |
+----------+
mysql> SELECT COUNT(*) FROM score;
+----------+
| COUNT(*) |
+----------+
| 173 |
+----------+
Insert New ‘Student’ (3)
To insert a new row into a table, for example, STUDENT:
INSERT INTO STUDENT VALUES ('JOESCHMO', 'M', '12345666');
Here we insert a new row with the indicated values above. It’s important that the datatype are correspondingly matched.
Now we can check if the row updated correctly by recounting the rows present in table STUDENT:
mysql> SELECT COUNT(*) FROM STUDENT;
+----------+
| COUNT(*) |
+----------+
| 32 |
+----------+
Now, what if we wanted to update the score table with an event for our new “student” using the previous INSERT command?
Inserting SCORE for STUDENT_ID into table (4)
mysql> INSERT INTO score VALUES (12345666, 10, 70);
we get:
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`studentdb`.`score`, CONSTRAINT `score_ibfk_1` FOREIGN KEY (`EVENT_ID`) REFERENCES `grade_event` (`EVENT_ID`))
Oh no! We can recall from:
mysql> describe score;
+------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+--------------+------+-----+---------+-------+
| STUDENT_ID | int unsigned | NO | PRI | NULL | |
| EVENT_ID | int unsigned | NO | PRI | NULL | |
| SCORE | int | NO | | NULL | |
+------------+--------------+------+-----+---------+-------+
EVENT_ID has a foreign key constraint such that EVENT_ID from score references the parent table grade_event’s EVENT_ID.
Thus, we can populate the parent table with dummy data and push our insert command to score
mysql> INSERT INTO grade_event VALUES ('2012-10-02', 'Q', 10);
Query OK, 1 row affected (0.01 sec)
and then successfully insert data:
mysql> INSERT INTO score VALUES (12345666, 10, 70);
Query OK, 1 row affected (0.01 sec)
Finding COUNT of “groups” of an “attribute” (5), (6)
The command below finds the count of each group in EVENT_ID. In this case, we are finding the count of each EVENT_ID in the score table:
mysql> SELECT EVENT_ID, COUNT(*) FROM score GROUP BY EVENT_ID;
+----------+----------+
| EVENT_ID | COUNT(*) |
+----------+----------+
| 1 | 29 |
| 2 | 30 |
| 3 | 31 |
| 4 | 27 |
| 5 | 27 |
| 6 | 29 |
| 10 | 1 |
+----------+----------+
7 rows in set (0.00 sec)
and finding it by STUDENT_ID:
mysql> SELECT STUDENT_ID, COUNT(*) FROM score GROUP BY STUDENT_ID;
+------------+----------+
| STUDENT_ID | COUNT(*) |
+------------+----------+
| 1 | 5 |
| 2 | 5 |
| 3 | 6 |
... // removed for readability
| 30 | 5 |
| 31 | 6 |
| 12345666 | 1 |
+------------+----------+
32 rows in set (0.00 sec)
Displaying Query by Value (7)
Let’s find the student who has the maximum score, minimum score, and their respective student names.
Find MIN SCORE:
mysql> SELECT
-> STUDENT.name, score.SCORE
-> FROM STUDENT INNER JOIN score
-> ON STUDENT.STUDENT_ID = score.STUDENT_ID
-> WHERE score.SCORE = (SELECT MIN(SCORE) FROM score);
+--------+-------+
| name | SCORE |
+--------+-------+
| Joseph | 7 |
+--------+-------+
1 row in set (0.00 sec)
Find MAX SCORE:
mysql> SELECT
-> STUDENT.name, score.SCORE
-> FROM STUDENT INNER JOIN score
-> ON STUDENT.STUDENT_ID = score.STUDENT_ID
-> WHERE score.SCORE = (SELECT MAX(SCORE) FROM score);
+-------+-------+
| name | SCORE |
+-------+-------+
| Megan | 100 |
+-------+-------+
1 row in set (0.00 sec)
How do we know this is correct? We can also check manually and cross reference each field. Noticably, the MAX score query is the same as the one for MIN score, only we filter for the MAX().
Group Query and Filter (8)
Database Triggers
A history of edits made to tables in a database.
A database trigger is a special type of stored program that automatically executes in response to certain events or actions occurring within a database. These events can include things like the insertion, update or deletion of data in a particular table or database.
Triggers in MySQL are written using SQL statements and are associated with a specific table or database. When the specified event occurs, the trigger’s code is executed, allowing you to perform a variety of actions such as logging changes, enforcing data integrity rules, or updating related tables.
example:
CREATE TRIGGER log_changes AFTER INSERT ON mytable
FOR EACH ROW
BEGIN
INSERT INTO log_table (user, action, timestamp)
VALUES (USER(), 'INSERT', NOW());
END;
Database triggers are a subset of stored programs.
Stored Programs
| Type | Description |
|---|---|
| Stored procedure | Can be called from an appljcation that has access to the database |
| Stored function | Can be called from a SQL statement. A stored function works much like the functions provided by MySQL that are described in chapter 9. |
| Trigger | Is executed in response to an INSERT, UPDATE, or DELETE statement on a specified table. |
| Event | ls executed at a scbeduled time. |
Midterm DB (3)
CREATE DATABASE MIDTERM;
USE MIDTERM;
CREATE TABLE COUNTRIES(
COUNTRY_ID CHAR(2) NOT NULL,
COUNTRY_NAME varchar (40),
REGION_ID INT);
ALTER TABLE COUNTRIES ADD PRIMARY KEY (COUNTRY_ID);
CREATE TABLE DEPARTMENTS(
DEPARTMENT_ID INT(4) NOT NULL,
DEPARTMENT_NAME varchar(30) NOT NULL,
MANAGER_ID INT(6),
LOCATION_ID INT(4));
CREATE INDEX DEPT_LOCATION_IX ON DEPARTMENTS (LOCATION_ID);
ALTER TABLE DEPARTMENTS ADD PRIMARY KEY (DEPARTMENT_ID);
CREATE TABLE EMPLOYEES(
EMPLOYEE_ID INT(6) NOT NULL,
FIRST_NAME varchar(20),
LAST_NAME varchar(25) NOT NULL,
EMAIL varchar(25) NOT NULL,
PHONE_NUMBER varchar (20),
HIRE_DATE DATE NOT NULL,
JOB_ID varchar(10) NOT NULL,
SALARY DOUBLE(8,2),
COMMISSION_PCT DOUBLE(2,2),
MANAGER_ID INT(6),
DEPARTMENT_ID INT(4));
CREATE INDEX EMP_DEPARTMENT_IX ON EMPLOYEES (DEPARTMENT_ID);
CREATE INDEX EMP_NAME_IX ON EMPLOYEES (LAST_NAME ASC, FIRST_NAME ASC);
CREATE INDEX EMP_JOB_IX ON EMPLOYEES (JOB_ID ASC);
CREATE TABLE JOBS(
JOB_ID varchar(10) NOT NULL,
JOB_TITLE varchar (35) NOT NULL,
MIN_SALARY INT(6),
MAX_SALARY INT(6));
ALTER TABLE JOBS ADD CONSTRAINT JOB_ID_PK PRIMARY KEY (JOB_ID);
CREATE TABLE JOB_HISTORY(
EMPLOYEE_ID INT(6) NOT NULL,
START_DATE DATE NOT NULL,
END_DATE DATE NOT NULL,
JOB_ID varchar(10) NOT NULL,
DEPARTMENT_ID INT(4));
CREATE TABLE LOCATIONS(
LOCATION_ID INT(4) NOT NULL,
STREET_ADDRESS varchar(40),
POSTAL_CODE varchar(12),
CITY varchar(30) NOT NULL,
STATE_PROVINCE varchar(25),
COUNTRY_ID CHAR(2));
CREATE INDEX LOC_CITY_IX ON LOCATIONS (CITY);
ALTER TABLE LOCATIONS ADD CONSTRAINT LOC_ID_PK PRIMARY KEY (LOCATION_ID);
2.
CREATE TABLE STUDENT_AUDIT (
name varchar(20),
GENDER enum('F','M'),
STUDENT_ID INT unsigned,
CREATE_DATE DATE,
ACTION_TYPE varchar(10),
USER varchar(20));
DELIMITER //
CREATE TRIGGER insert_trigger
AFTER INSERT ON STUDENT
FOR EACH ROW
BEGIN
INSERT INTO STUDENT_AUDIT (name, GENDER, STUDENT_ID, CREATE_DATE, ACTION_TYPE, USER)
VALUES (NEW.name, new.GENDER, new.STUDENT_ID, NOW(), 'INSERTED', USER());
END //
DELIMITER //
CREATE TRIGGER delete_trigger
AFTER DELETE ON STUDENT
FOR EACH ROW
BEGIN
INSERT INTO STUDENT_AUDIT (name, GENDER, STUDENT_ID, CREATE_DATE, ACTION_TYPE, USER)
VALUES (OLD.name, OLD.GENDER, OLD.STUDENT_ID, NOW(), 'DELETED', USER());
END //
DELIMITER //
CREATE TRIGGER update_trigger
AFTER UPDATE ON STUDENT
FOR EACH ROW
BEGIN
INSERT INTO STUDENT_AUDIT (name, GENDER, STUDENT_ID, CREATE_DATE, ACTION_TYPE, USER)
VALUES (NEW.name, new.GENDER, new.STUDENT_ID, NOW(), 'UPDATED', USER());
END //
INSERT INTO STUDENT(name, GENDER, STUDENT_ID) VALUES('test1', 'M', '111');
UPDATE STUDENT SET name='test22' WHERE name='test1';
DELETE FROM STUDENT WHERE name='test22';
Database Transactions
Transactions in MySQL are used to ensure data integrity and consistency. They provide a way to guarantee that multiple operations on the database are completed successfully or not at all, even if the database is accessed by multiple users concurrently.
A transaction typically consists of four main operations, known as the ACID properties:
| ACID Type | Property Description |
|---|---|
| Atomicity | This property ensures that either all the operations within the transaction are completed successfully, or none of them are completed at all. |
| Consistency | This property ensures that the database remains in a valid state before and after the transaction. It guarantees that all constraints, such as referential integrity and data type constraints, are satisfied. |
| Isolation | This property ensures that the effects of one transaction are not visible to another transaction until it is completed. |
| Durability | This property ensures that the results of a completed transaction are permanent and can survive system failures, such as power outages or crashes. |
Lab
For this lab, we will do the following:
-
Use STUDENTDB database to work on the tables.
-
In this exercise, you will first open 2 sessions by connecting to mysql database. One session is used to either insert, update, delete data from the tables. The second session is used to check the data.
-
You should first turn OFF autocommit option. Please see class video to turn off autocommit.
-
From the first session, insert a new student into STUDENT table. Check from 2nd session if student was inserted or not. If it is not inserted, write a reason and if it is inserted take a screenshot.
-
From the first session, update data into SCORE table by updating score for student_id=10 and event_id=5 to a new value. Check the score from 2nd session to see if it is inserted or not. Take a screenshot. Go back to 1st session and COMMIT the data and check the data in the 2nd session.
-
From the 1st session, delete from SCORE table where student_id=20 and event_id=5. Check if the data is deleted or not from 2nd session. Take a screenshot. Go back now to 1st session and perform ROLLBACK. Now check the data from both 1st and 2nd session. Take a screenshot.
use studentdb;
SET autocommit = 0; --set autocommit option OFF
INSERT INTO STUDENT (name, GENDER, STUDENT_ID) VALUES ('Joey Schmoey', 'M', 1001);
SELECT * FROM STUDENT; --check from second session
Noticable however, the 2nd session does not update the table. Recall that earlier, we turned off autocommit. From the mysql manual:
By default, MySQL runs with autocommit mode enabled. This means that, when not otherwise inside a transaction, each statement is atomic, as if it were surrounded by START TRANSACTION and COMMIT.
Further down this entry in the manual:
After disabling autocommit mode by setting the autocommit variable to zero, changes to transaction-safe tables (such as those for InnoDB or NDB) are not made permanent immediately. You must use COMMIT to store your changes to disk or ROLLBACK to ignore the changes.
UPDATE score SET STUDENT_ID=20, EVENT_ID=15 WHERE STUDENT_ID=10 AND EVENT_ID=5;
Relational Design
Overview
This section covers relational design, where mega relations and their properties may be decomposed into final sets of relations that are normal form. These come in the form of Functional dependencies creating Boyce-Codd Normal Forms, and Multivalued dependencies creating fourth normal forms.
Functional Dependencies
Below are definitions: Functional Dependency: A unique attribute has another attribute that must always occur given said unique attribute. It is said the other attribute has a functional dependency on the unique attribute. Boyce-Codd Normal Form: If $A->B$ then $A$ is a key.
$$
\forall t,u \in Student, t.GPA = u.GPA \rArr t.priority = u.priority
\ GPA \rArr priority
$$
This is an example of a functional dependency.
We also want “lossless” joins after decomposition.
Review
Review of the following topics:
- Relational Database Modelling and Design
- SQL Constraints and Triggers
- Indexes and Authorization
Example questions:
- Question 1: Relational Schema Design (4 points)
- Question 2: Schema Definition and SQL Constraints (4 points)
- Question 3: SQL Assertions (4 points)
- Question 4: SQL Triggers (4 points)
- Question 5: SQL Triggers (4 points)
Relational Database Modeling and Design:
Relational database modeling involves the process of defining the structure of a database, including tables, relationships, and constraints, to ensure efficient data storage and retrieval. Key concepts include:
-
Entities and Attributes:
- Entities are objects or concepts with an independent existence (e.g., Customer, Product).
- Attributes are properties that describe the characteristics of entities.
-
Relationships:
- Relationships establish connections between entities.
- Types of relationships include one-to-one, one-to-many, and many-to-many.
-
Normalization:
- Normalization is the process of organizing data to reduce redundancy and dependency.
- It involves breaking down tables into smaller, related tables to minimize data duplication.
-
ER Diagrams:
- Entity-Relationship (ER) diagrams visually represent the database structure, showing entities, attributes, and relationships.
SQL Constraints and Triggers:
-
Constraints:
- Constraints ensure data integrity and accuracy.
- Common constraints include PRIMARY KEY, FOREIGN KEY, UNIQUE, NOT NULL, ATTRIBUTE, TUPLE, GENERAL ASSERTION.
- They prevent the entry of invalid or inconsistent data into the database.
-
Triggers:
- Triggers are special stored procedures that automatically execute in response to predefined events (e.g., INSERT, UPDATE, DELETE).
- They are used to enforce business rules, perform auditing, and maintain referential integrity.
Indexes and Authorization:
-
Indexes:
- Indexes are data structures that enhance query performance by allowing quicker data retrieval.
- They provide a fast access path to rows based on the values in one or more columns.
- Common types include B-tree, hash, and bitmap indexes.
-
Authorization:
- Authorization involves controlling access to database objects (tables, views, procedures) based on user roles and privileges.
- Roles define sets of privileges, and users are assigned to roles.
- Privileges include SELECT, INSERT, UPDATE, DELETE, and EXECUTE.
Sample Questions and Answers:
Question 1: Relational Schema Design (4 points)
Question: Explain the importance of normalization in relational schema design. Provide an example scenario where normalization is beneficial.
Answer: Normalization is crucial in relational schema design to minimize data redundancy and dependency. It ensures that data is stored efficiently, reducing the risk of anomalies during updates, insertions, and deletions. For example, consider a denormalized table storing customer data along with order details. If a customer’s address changes, updating multiple records becomes error-prone. Normalizing this data into separate tables like Customers and Orders eliminates such issues.
Question 2: Schema Definition and SQL Constraints (4 points)
Question: Describe the role of SQL constraints in maintaining data integrity. Provide an example of each of the following constraints: PRIMARY KEY, FOREIGN KEY, and CHECK.
Answer: SQL constraints play a vital role in ensuring data integrity by defining rules that the data must adhere to.
- PRIMARY KEY: Ensures uniqueness of a column and prevents NULL values. Example:
CREATE TABLE Employees (EmployeeID INT PRIMARY KEY, Name VARCHAR(50)); - FOREIGN KEY: Maintains referential integrity by linking two tables based on a column. Example:
CREATE TABLE Orders (OrderID INT PRIMARY KEY, CustomerID INT FOREIGN KEY REFERENCES Customers(CustomerID)); - CHECK: Enforces a condition on a column. Example:
CREATE TABLE Students (StudentID INT, Age INT CHECK (Age >= 18));
Question 3: SQL Assertions (4 points)
Question: Explain the concept of SQL assertions and provide a practical example of how they can be used to enforce business rules.
Answer: SQL assertions are conditions specified in a CREATE ASSERTION statement to enforce business rules that span multiple rows or tables. For instance, consider an assertion to ensure that the total quantity of items in an order does not exceed the available stock. This prevents inconsistent data, ensuring that the business rule “order quantity must not exceed stock” is always maintained.
Question 4: SQL Triggers (4 points)
Question: Discuss the role of SQL triggers in a database system. Provide an example scenario where a trigger would be beneficial.
Answer: SQL triggers are special stored procedures that automatically execute in response to predefined events. They play a crucial role in maintaining data consistency and enforcing business rules. For example, consider a trigger that automatically updates the “last modified” timestamp whenever a row in the Orders table is updated. This ensures accurate tracking of when orders were last modified without manual intervention.
Question 5: SQL Triggers (4 points)
Question: Differentiate between BEFORE and AFTER triggers in SQL. Provide a scenario for each where their usage is appropriate.
Answer: BEFORE triggers execute before the triggering event (e.g., INSERT, UPDATE), allowing modification of data before it is written to the database. They are useful for validating or modifying data before it is stored. For example, a BEFORE INSERT trigger can be employed to automatically set a default value for a column if none is provided.
AFTER triggers, on the other hand, execute after the triggering event, making them suitable for tasks that should occur after data modification. For instance, an AFTER UPDATE trigger could be used to log the changes made to a specific table in an audit log, providing a historical record of updates.